NB: in questa presentazione condivido riflessioni su argomenti di mia recente acquisizione, senza pretesa di originalità, completezza, precisione, etc. Alla fine mostretò una slide in cui si troveranno indicazioni per esplorazioni più approfondite.
Chiacchiere intuitive
L'impero del deep learning
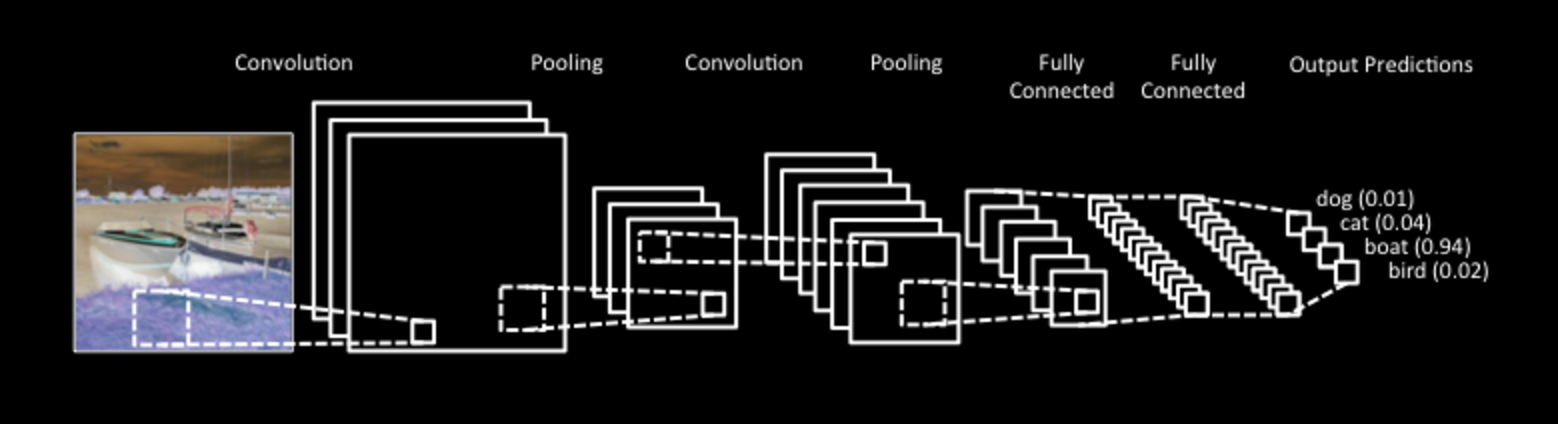
Il paradigma ML oggi dominante è il deep learning: potente, preciso, pervasivo. L'idea è vecchia di 30 anni (reti neurali) o anche di 200 anni (convoluzione). Ma è l'attuale disponibilità di calcolo e storage che consente di scatenarne la potenza...
Reti ispirate al nostro cervello: ma il cervello funziona così?
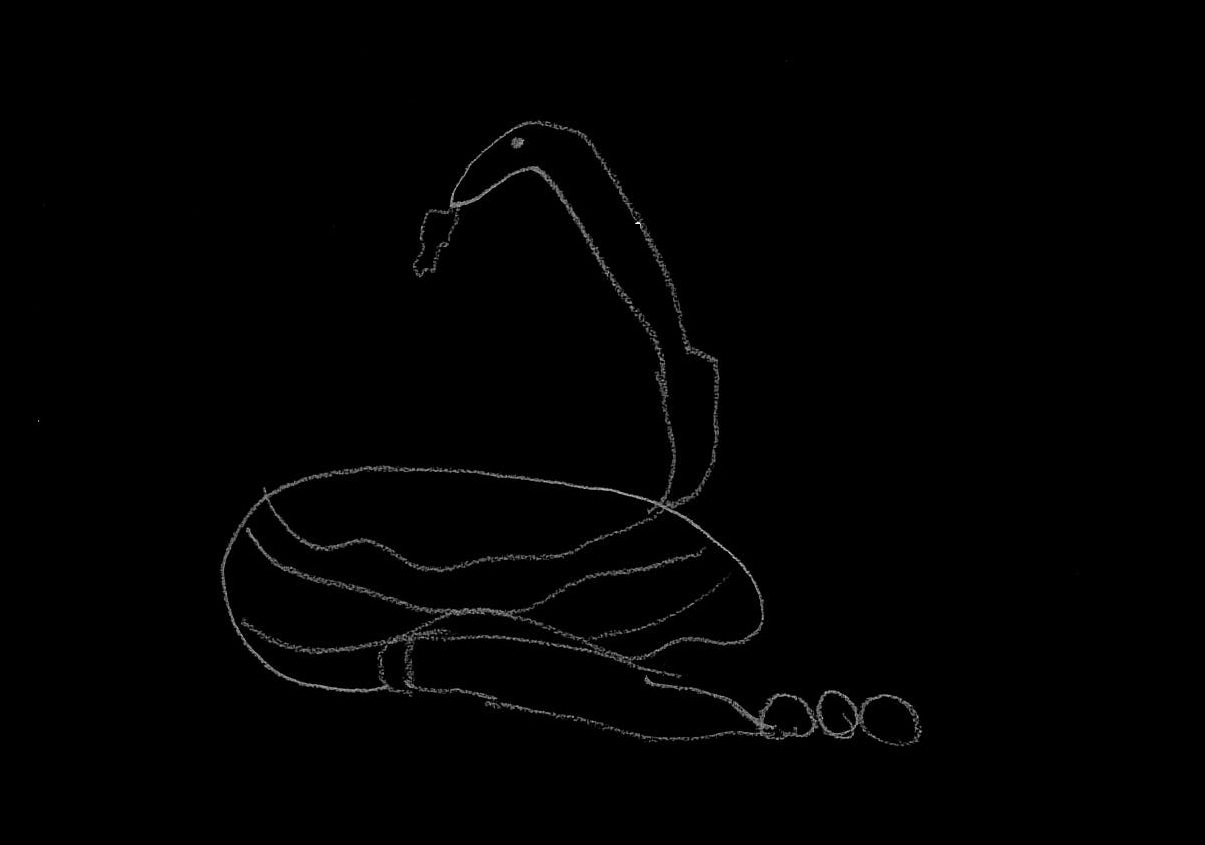
Riconoscere un maiale...
Un bimbo non ne ha visti migliaia, gli bastano pochi esempi per imparare a riconoscerli...
"Livietta, mi disegni un animale?"
... quanti serpenti a sonagli ha visto in vita sua?
"No tesoro, un animale più comune!"
Certo, di T-Rex ne ha visti di più...
"Vabbe', disegna un gatto..."
Lo riconosciamo da naso e orecchie...
Se lo comprendi lo comprimi
Nel chiedere questi disegni ho detto a mia figlia di farli rapidamente e senza entrare in dettagli (sa ovviamente disegnare meglio a 7 anni!).
Le ho chiesto cioè di comprimere le informazioni sugli animali che doveva disegnare e lei ha saputo farlo perché comprendeva cosa voleva disegnare.
Ha compreso il serpente a sonagli, il T-Rex e il gatto al punto da saperne sintetizzare gli elementi essenziali e rappresentarli in modo minimalistico. Lei ha compresso...
... e voi avete compreso (li avete riconosciuti!)
Se non sai comprimerlo non l'hai compreso
A scuola ci facevano fare i riassunti (comprimere un testo) per vedere se lo avevamo compreso.
Fondamenta teoriche
Teoria algoritmica dell'informazione
Nel 1965 il geniale matematico sovietico Andrej Nicolaevič Kolmogorov, e indipendentemente anche Ray Solomonoff e Gregory Chaitin, definirono un concetto di complessità che lega la quantità di informazione contenuta in una stringa alla difficoltà di scrivere un algoritmo che la generi: la stringa è tanto più densa di informazioni quanto più è lungo l'algoritmo che la descrive.
Sulle spalle dei giganti
Kolmogorov mise in relazione le due teorie che stanno alla base dell'ICT: la teoria della calcolabilità di Alonzo Church e Alan Turing e la teoria dell'informazione di Claude Shannon.
Algoritmi e programmi
Per comprendere la teoria di Kolmogorov ricordiamo che:
un programma è un testo che esprime una procedura di calcolo in un certo linguaggio di programmazione.
Un algoritmo può esser visto come una funzione calcolabile (tesi di Church), cioè per cui esista un programma P che la implementi: a un input x, P associa un output y come prescrive l'algoritmo.
Dunque un algoritmo è un oggetto matematico, mentre un programma è un testo, tipicamente un file all'interno della memoria di un computer.
Programmi e interpreti
Fissiamo un linguaggio di programmazione e un interprete per quel linguaggio.
L'interprete associa a un programma P e a un input x un output y ottenuto eseguendo il programma sull'input dato.
Possiamo supporre che x e y siano stringhe, del pari di P, e scriviamo
P(x) = y
per denotare l'esecuzione di P sull'input x per ottenere l'output y.
Un solo algoritmo, molti programmi
Dato un algoritmo, esistono infiniti programmi che lo implementano: per esempio l'algoritmo che chiede un numero x e ne stampa il doppio y = 2x può essere così, più o meno ottusamente, espresso in Python:
x = int(input()) x = int(input()) x = int(input())
y = 2 * x y = x y = 0
print(y) y = y + x i = 1
print(y) while i <= x :
y = y + 2
i = i + 1
print(y)
Dato un algoritmo esiste sempre almeno un programma che lo implementa, e quindi ne esiste uno di lunghezza minima.
Complessità condizionale di Kolmogorov
Date due stringhe x e y, la complessità condizionale di y data x è il numero
K(y|x) = min { |P| : P(x) = y }
dove con |P| indichiamo la lunghezza del testo (stringa) P.
Dunque la complessità condizionale di y dato x è la minima lunghezza di un programma P che dato x come input produca y come output.
Complessità di Kolmogorov
Data una stringa y, la complessità di Kolmogorov di y è il numero
K(y) = K(y|ε) = min { |P| : P() = y }
(ε = stringa vuota). Cioè: la complessità di Kolmogorov di una stringa è la lunghezza minima di un programma che la generi.
Se K(y) ≥ |y|, cioè se la complessità di una stringa è maggiore o uguale alla lunghezza della stringa, diciamo che y è incomprimibile: questo è, in un senso che si può precisare, sinonimo di casualità...
Voluttà matematica
Alcune proprietà della complessità di Kolmogorov K(y):
K(y)non è una funzione calcolabile: non esiste nessun algoritmo in grado di esprimerla.
Se X = {Xn} è una famiglia di variabili aleatorie i.i.d. ciascuna delle quali ha come valore una lettera di un alfabeto, scrivendo Xn = X1⋯Xn si ha la seguente relazione fra entropia e complessità:
┌ ┓
lim E│1 K(Xn|n)│ = H(X)
n └n ┘
dove H(X) è il tasso di entropia del processo X.
Approssimare la complessità
Anche se né K(y|x) né K(y) sono effettivamente calcolabili, si possono stimare, e una buona stima è data dagli algoritmi di compressione.
Infatti se la complessità di Kolmogorov di y è bassa, possiamo pensare a un programma P che genera y come a una versione compressa di y.
Quindi possiamo approssimare K(y) con la lunghezza della stringa ottenuta comprimendo y compressa "il più possibile".
Ma è possibile determinare la compressione ottimale di una stringa qualsiasi?
Compressori ottimali
Molti algoritmi di compressione sfruttano le caratteristiche delle stringhe che vogliono comprimere (per esempio ce ne sono di espressamente concepiti per comprimere il DNA come DNAcompress).
Tuttavia esistono anche degli algoritmi di compressione che si applicano a stringhe qualsiasi e che offrono, asintoticamente (cioè nel lungo periodo, al limite su stringhe infinite), risultati ottimali.
Un compressore asintoticamente ottimale è quello di Lempel-Ziv, pubblicato nel 1978.
Algoritmo di Lempel-Ziv
Questo algoritmo è solitamente usato nella teoria per approssimare K(x) con la lunghezza della stringa ottenuta dalla compressione di x. LZ è molto usato anche nella pratica: lo usate ogni volta che visualizzate un file .gif.
Applicazioni ed esempi
Applicazioni: modellizzazione dei dati
L'idea di comprimere i dati prima di confrontarli è stata impiegata in molti contesti, come per esempio nelle tecniche di modellazione dei dati.
Un esempio è il cosiddetto principio del Minimum Description Length, basato sull'idea che il miglior modo di trovare un pattern in un insieme di dati è di costruire un modello che consenta una descrizione minimale di questi dati: in questo senso si propone come una approssimazione (calcolabile) della complessità di Kolmogorov.
La compressione dei dati per la loro comprensione è anche ricorrente nel "data mining".
Per esempio, la complessità condizionale può essere utilizzata per definire misure di similarità e distanze che hanno performance notevoli nei problemi di classificazione e clustering (ne vedremo degli esempi). In particolare consentono di classificare dati di ogni tipo, e confrontare contemporaneamente testi, immagini, suoni, etc.
Risultati notevoli in questo campo sono dovuti a Paul Vitanyi.
Applicazioni: biologia molecolare
La comprensione tramite la compressione funziona bene su stringhe molto lunghe, come per esempio le molecole alla base dei processi biologici (DNA, RNA, etc.): esistono notevoli metodi anche predittivi che consentono lo studio di queste molecole confrontando le loro "compressioni".
Per esempio è possibile predire se una sequenza di un DNA corrisponda o meno a un certo gene e quindi automatizzare l'analisi del DNA.
Usando la complessità condizionale di Kolmogorov, possiamo definire una "distanza" fra due stringhe nel modo seguente:
distK(x,y) = K(x|y) + K(y|x)
K(xy)
cioè la distanza si ottiene sommando le complessità condizionali di x rispetto a y e dividendo per la complessità della stringa xy ottenuta giustapponendo le stringhe x e y.
(Per i matematici: a essere sinceri non è una vera distanza perché la disuguaglianza triangolare vale a meno di una approssimazione.)
Prendere le distanze dalla complessità...
Poiché la complessità di Kolmogorov non è calcolabile, la approssimiamo come
distC(x,y) = C(x|y) + C(y|x)
C(xy)
dove C(x) denota la lunghezza di x compressa con un compressore fissato, e C(x|y) la lunghezza della stringa compressa ottenuta da x tramite un compressore che sappia già come comprimere y.
È applicata con successo al clustering di testi e del DNA.
Compression Dissimilarity Measure
Un approccio più semplice ma efficace è il seguente: dato un compressore C e scrivendo C(x) per la lunghezza di x dopo la compressione, possiamo definire una misura di dissimilarità come
CDMC(x,y) = C(xy)
C(x) + C(y)
Questa misura è tanto prossima a 1 quanto più le stringhe sono dissimili (ma NB: CDM(x,x) > 0), ed è stata applicata con successo a un parameter-free clustering di testi, DNA e all'anomaly detection di elettrocardiogrammi, video ma anche all'analisi automatica dei log di dispositivi e sistemi.
Esempio: anomaly detection con CDM
Ho generato 20 curve sinusoidali, sen(x + α), in mezzo alle quali ho nascosto la curva (sen x)/x. Ogni curva è rappresentata dal vettore di 40 suoi valori delle ordinate (è anche possibile perturbare a caso la curva).
Ho poi brutalmente convertito i vettori in stringhe e, per ciascuno di essi, ho calcolato la somma delle CDM dagli altri vettori: l'idea è che l'outlier corrisponda alla somma massima (NB: 0 < CDM ≤ 1 è tanto più vicina a 1 quanto meno simili sono le stringhe).
Se in questo modo idiota trovo l'outlier pensate che si può fare con algoritmi seri!!!
Esempio: anomaly detection con CDM
Outlier:
N punti:
Perturbazione:
...
Normalized Compression Distance
Si tratta di una distanza vera e propria fra stringhe definita, dato un compressore C e scrivendo C(x) per la lunghezza di x dopo la compressione, come
NCDC(x,y) = C(xy) - min(C(x),C(y))
max(C(x),C(y))
Questa distanza è tanto più prossima a 0 quanto più le stringhe sono simili, ed è stata applicata con successo alla ricostruzione dei dendrogrammi filogenetici (classificazione delle specie) a partire dal DNA mitocontriale, al clustering gerarchico di tipi di dato qualsiasi, e al web semantico.
Esempio: classificazione con NCD
In questo esempio classifichiamo documenti di testo del celebre dataset 20 Newsgroups, che colleziona 20 classi di post di vecchi newsgroups.
Si prendono un massimo di 1000 file da due categorie simili (rec.sport.baseball e rec.sport.hockey), si calcola per ogni elemento la somma delle distanze NCD da tutti gli altri e si divide in due il dataset prendendo la mediana di queste somme: poi si assegnano a una classe gli elementi con le somme al di sotto della mediana e a un'altra i rimanenti.
L'algoritmo ricostruisce completamente le due classi! Di nuovo una banalità...
Esempio: classificazione con NCD
# di elementi in rec.sport.baseball:
# di elementi in rec.sport.hockey:
Precision: 0
Recall: 0
Per saperne di più...
Seguono alcuni interessanti lavori che ho utilizzato nello scrivere queste slide.
Cilibrasi, Vitanyi. Clustering by compression IEEE Trans. Information Theory 51 (2005), no.4, 1523-1545.
Vitanyi. Compression-based similarity Proc. IEEE 1st Int. Conf. Data Compression, Communication and Processing, Palinuro, Italy, June 21-24, (2011) pp.111-118.








 Nel 1965 il geniale matematico sovietico Andrej Nicolaevič Kolmogorov, e indipendentemente anche Ray Solomonoff e Gregory Chaitin, definirono un concetto di complessità che lega la quantità di informazione contenuta in una stringa alla difficoltà di scrivere un algoritmo che la generi: la stringa è tanto più densa di informazioni quanto più è lungo l'algoritmo che la descrive.
Nel 1965 il geniale matematico sovietico Andrej Nicolaevič Kolmogorov, e indipendentemente anche Ray Solomonoff e Gregory Chaitin, definirono un concetto di complessità che lega la quantità di informazione contenuta in una stringa alla difficoltà di scrivere un algoritmo che la generi: la stringa è tanto più densa di informazioni quanto più è lungo l'algoritmo che la descrive.



