
Vettori e parole: l'algebra del significato

Paolo Caressa — Roma, 3 maggio 2017
Paolo Caressa <http://www.caressa.it>
Roma, 3 maggio 2017
Paolo Caressa — Roma, 3 maggio 2017
Una chiacchierata informale e divulgativa che introdurrà ad alcune idee di base della linguistica computazionale, ai modelli matematici utilizzati comunemente nella rappresentazione della semantica del linguaggio naturale, e ad alcuni algoritmi interessanti emersi di recente (2013 in poi).
Alcune slide contengono il codice di algoritmi e dati per poter mostrare applicazioni complete dei concetti esposti, in particolare sul recente algoritmo Word2Vector.
Nessuna pretesa di: originalità, completezza, precisione, etc.
Enjoy!
Le lingue sono caratterizzate da (C.W. Morris, 1938):
?


Per sé presa, la frase non è semplicemente ambigua, ma "anfibologica", cioè può avere due significati distinti a parità di sintassi: è il contesto, o l'intenzione del narratore, che consente di capire il significato vero.
Di ritorno dalla Corea riferì attonito: "ho visto mangiare un cane".
Dopo aver guardato dalla finestra, sulla strada, disse: "ho visto mangiare un cane"
(e se la finestra è in Corea?)
") Il sillogismo categorico è una formalizzazione di un frammento del linguaggio per svolgere deduzioni in modo automatico:
Il sillogismo categorico è una formalizzazione di un frammento del linguaggio per svolgere deduzioni in modo automatico:
Socrate e Platone sono uomini
Gli uomini sono mortali
dunque
Socrate e Platone sono mortali
Indubitabile, no?
1858-1932")
Pietro e Giovanni sono apostoli
Gli apostoli sono dodici
dunque
Pietro e Giovanni sono dodici
Cosa abbiamo sbagliato?!?
Una interpretazione di un linguaggio è un modo di "mappare" il linguaggio su degli oggetti matematici, come per esempio gli insiemi
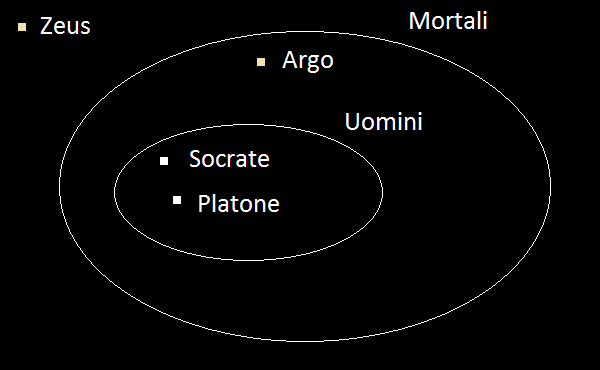
Socrate ∈ Uomini ∧ Platone ∈ Uomini,
Uomini ⊂ Mortali
⊦ Socrate ∈ Mortali ∧ Platone ∈ Mortali
Infatti se A e B sono insiemi, allora A ⊂ B se e solo se per ogni x ∈ A si ha pure che x ∈ B.
Nel caso dei "dodici apostoli", il dire "gli apostoli sono dodici" è una abbreviazione per "la cardinalità dell'insieme degli apostoli è 12": dunque la seconda affermazione è "fuori dal modello", in quanto non è insiemistica ma numerica. Una possibile formalizzazione diviene
Pietro ∈ Apostoli ∧ Giovanni ∈ Apostoli,
Card(Apostoli) = 12
⊦ Card({Pietro, Giovanni}) = 12
che è una falsa deduzione.
Una corretta formalizzazione logico-matematica consente di sciogliere l'ambiguità linguistica e di dirimere i domini semantici di ciascuna frase: le proprietà matematiche dei domini semantici consentono poi di spiegare il paradosso.
Questo semplice esempio mostra come si possa studiare (parte di) un linguaggio usando i sistemi formali della logica matematica per la sintassi e la teoria degli insiemi, o dei suoi frammenti, per la semantica.
A partire dagli anni '90, grazie alla crescente capacità computazionale e alla rinascita dell'AI (in particolare all'introduzione dei metodi del ML), si sono potuti applicare metodi di ottimizzazione e di inferenza statistica a collezioni molto ampie di testi.
A differenza dei metodi mediati dalla teoria dei linguaggi formali, il fulcro di questo approccio è la mappatura dei termini linguistici su oggetti numerici (per esempio numeri, vettori, matrici, etc.) per poterli poi elaborare con gli algoritmi di ML.
Questi metodi sono tipicamente indipendenti dalla lingua.
Il principale modello matematico per qualsiasi cosa si possa immaginare è lo spazio vettoriale, cioè un insieme di oggetti (chiamati punti o vettori) che si possono sommare fra loro e moltiplicare per numeri in modo che valgano le usuali regole dell'algebra dei vettori nel piano e nello spazio: ogni spazio vettoriale ha una ben precisa dimensione.
La teoria degli spazi vettoriali è particolarmente semplice in quanto è "categorica": fissata una dimensione tutti gli spazi vettoriali di quella dimensione sono equivalenti fra loro (i matematici dicono isomorfi).
Il "modello standard" di uno spazio vettoriale di dimensione N è l'insieme RN delle N-ple ordinate di numeri reali (x1, ..., xN): nei casi N=2, N=3 ritroviamo il classico concetto di piano e spazio cartesiano.
Possiamo dotare questo insieme di operazioni indotte "termine a termine" da quelle fra numeri (α è un numero)
(x1, ..., xN) + (y1, ..., yN) = (x1+y1, ..., xN+yN)
α(x1, ..., xN) = (αx1, ..., αxN)
x=(,) y=(,) x+y=(0,0)
La lunghezza (euclidea) di un vettore è il numero non negativo
______________
|x| = √x12 + ... + xN2
Esistono altre possibili distanze (tutte topologicamente equivalenti).
Questa è direttamente ispirata al teorema di Pitagora e corrisponde, nel piano e nello spazio cartesiani, alla usuale distanza euclidea.
La distanza (euclidea) fra due vettori è la lunghezza della loro differenza
________________________
d(x,y) = |x-y| = √(x1-y1)2 + ... + (xN-yN)2
Se due vettori hanno distanza minore di δ allora vuol dire che uno dei due è sempre incluso in ogni "palla" di centro l'altro e raggio maggiore di δ.
La correlazione (o "similarità") fra due vettori è un numero fra -1 e 1 ottenuto come
c(x,y) = x1y1 + ... + xNyN
|x|×|y|
Questo valore si chiama anche "distanza del coseno", essendo pari al coseno dell'angolo fra i due vettori: questo angolo è 1 se i vettori sono allineati, -1 se sono opposti, 0 se sono ortogonali.
x = (,)
y = (,)
d(x,y) = 0
c(x,y) = 0
Se abbiamo un insieme di oggetti possiamo mapparli sui punti di uno spazio vettoriale di dimensione N in molti modi: la "furbizia" nella scelta del modello sta nel farlo in modo che oggetti simili siano mappati su punti vicini, nel senso che la loro distanza è piccola.
Questi modelli si chiamano modelli continui perché i valori delle componenti dei vettori variano fra i numeri reali (rappresentabili nel computer); incidentalmente, la funzione che applica gli oggetti sui punti del modello vettoriale dovrebbe essere tale che punti vicini nel modello provengono da punti vicini nel dominio.
Tipicamente i modelli vettoriali sono tanto più precisi ed espressivi quanto maggiore è la dimensione degli spazi vettoriali coinvolti: per esempio, un modo per codificare un documento di testo potrebbe essere mapparlo su un punto di uno spazio vettoriale a N dimensioni dove N è il numero di parole possibili per quel documento.
Naturalmente questo implica dover, a priori, considerare spazi vettoriali di dimensioni dell'ordine delle migliaia, decine di migliaia o anche centinana di migliaia.
Per questo si applicano delle tecniche di "riduzione della dimensione" che consentono di proiettare questi spazi su spazi con basse dimensioni mantenendo in qualche modo la coerenza e il significato dei dati rappresentati.
Esempi di queste tecniche sono:
Se abbiamo un corpus {D1,...,Dk} di documenti di testo, e se {W1,...,Wh} sono le parole che occorrono almeno una volta in qualche documento, possiamo formare una matrice
| D1 | ... | Dk | |
|---|---|---|---|
| W1 | x11 | ... | x1k |
| ⁝ | ⁝ | ⁝ | ⁝ |
| Wh | xh1 | ... | xhk |
dove xij è un numero (solitamente fra 0 e 1) che descrive la rilevanza della parola Wi per il documento Dj.
Per popolare la matrice precedente (migliaia/miriadi di righe, centinaia/migliaia di colonne) si possono usare diverse misure della rilevanza di una parola in un testo e in un corpus di testi: un esempio classico è la TFIDF:
xij = #{occorrenze di Wi in Dj} ×
× log (k / #{documenti D tali che Wi ∈ D})
Si premiano i termini che compaiono spesso in un documento ma non troppo spesso negli altri documenti, cioè le parole che "caratterizzano" un documento nel corpus.
Lo schema precedente (che viene dalle classiche tecniche di "recupero informazioni") può essere usato per determinare un modello semantico delle parole di un corpus, considerando come documenti non interi testi ma delle "finestre" di parole costruite attorno alla parola da analizzare.
In questo modo, il contesto di una parola sono le parole che occorrono nelle "vicinanze" di essa in un testo (per esempio fra le 5 parole che la precedono e le 5 che la seguono): la matrice diviene dunque una "matrice di co-occorrenze".
Si tratta di una tecnica che consiste nell'analizzare un corpus estraendone parole e contesti, usandoli per formare la matrice che poi viene ridotta nelle sue dimensioni usando algoritmi di algebra lineare (SVD).
Le righe di questa matrice ridotta costituiscono quindi dei vettori numerici associati alle parole, che ne codificano la semantica, in modo che parole con significato analogo tendono a essere rappresentate da vettori "vicini" fra loro nel senso della distanza euclidea, o della correlazione.
") The correlation between language and meaning is much greater when we
consider connected discourse. To the extent that formal (distributional) structure
can be discovered in discourse, it correlates in some way with the substance of
what is being said; this is especially evident in stylized scientific discourse.
The correlation between language and meaning is much greater when we
consider connected discourse. To the extent that formal (distributional) structure
can be discovered in discourse, it correlates in some way with the substance of
what is being said; this is especially evident in stylized scientific discourse.
Zellig Harris (1909-1992)
")
A word is characterized by the company it keeps
John Rupert Firth (1890-1960)
Si tratta di una tecnica per calcolare i vettori associati alle parole usando una rete neurale (con un layer interno), in una modalità non supervisionata.
In pratica, per ogni parola del corpus si produce un vettore binario w, di dimensione pari alla cardinalità N del corpus, che rappresenta la parola e lo si usa come input per la rete, che in output fornisce una distribuzione di probabilità y sullo "spazio" delle parole, dunque ancora un vettore di dimensione N.
La rete si addestra a produrre la distribuzione di probabilità y in modo che dalla parola di input si possa predire il contesto (skipgram model): un algoritmo alternativo deduce la parola dal contesto (CBOW model).
Cioè, nel caso CBOW, yi è la probabilità che la parola wi segua la parola fornita in input alla rete.
Il layer interno della rete neurale accumula dei valori prodotti via via che le parole del testo sono presentate alla rete, e conserva quindi memoria dei contesti al cui interno si manifestano le parole esaminate dalla rete: questo è l'elemento cruciale dell'algoritmo.
")
s(t) = Uw(t) + Ws(t-1)
y(t) = Vs(t)
Sia y che s sono filtrati tramite delle funzioni: con la rappresentazione "soft-max" il primo, con una sigmoide f(z) il secondo.
I vettori associati alle parole, cioè il reale output che interessa per il modello semantico distribuito, sono estratti come colonne dalla matrice U che fornisce il collegamento fra il layer di input e il layer interno della rete neurale.
Questo algoritmo può essere implementato in modo efficiente e, per corpus abbastanza vasti (almeno miliardi di parole), produce risultati molto accurati migliorando di molto le prestazioni dei precedenti algoritmi di analisi semantica distribuita.
Un aspetto che ha del miracoloso di questo algoritmo è che alcune relazioni semantiche sono codificate tramite operazioni lineari fra i vettori delle parole corrispondenti.
Per esempio: se scriviamo v(w) per il vettore associato alla parola w, e w(v) per la parola corrispondente al vettore più vicino al vettore v, troviamo che
w(v("king") - v("man") + v("woman")) = "queen"Ulteriori risultati ottenuti dagli inventori di Word2Vector.
w(v("bigger") - v("big") + v("cold")) = "colder"w(v("Paris") - v("France") + v("Italy")) = "Rome"w(v("sushi") - v("Japan") + v("Germany")) = "bratwurst"w(v("Windows") - v("Microsoft") + v("Google")) = "Android"L'algoritmo Word2Vector è stato implementato da uno dei suoi creatori, Thomas Mikolov, in un C duro e puro, e si scarica dal sito di Google: https://code.google.com/archive/p/word2vec/.
Dal sito si scarica il file .c del programma che produce i vettori, altri programmi che illustrano possibili e semplici applicazioni di questi vettori, e link a dataset, anche di miliardi di parole, per addestrare l'algoritmo.
Per queste slide ho usato un dataset "piccolo" (70K parole, dimensione 200) in lingua inglese, pertanto le performance degli script seguenti non saranno esaltanti, ma rendono l'idea: con corpus da milioni di vettori e una dimensione di almeno 300 si ottengono risultati migliori, con miliardi di vettori e almeno 400 dimensioni si hanno performance spettacolari.
I programmini JavaScript nelle slide seguenti mostrano come alcune relazioni semantiche si codifichino in relazioni lineari: per esibire in 2D i risultati ho usato l'algoritmo t-SNE per proiettare i vettori di 200 componenti nel piano.
Semantica dell'analogia codificata nei vettori: si determina una parola che ne corrisponde a un'altra dato un certo schema di corrispondenza: questo semplicemente con operazioni lineari!
sta a come sta a ...
Usando la correlazione possiamo determinare le k= parole più simili a una parola data:
Q&A
Credits
Wikipedia, http://www.meteoweb.eu per le immagini.
Google Code per il codice di Word2Vector.
Matt Mahoney per il dataset utilizzato.
Andrej Karpathy per la libreria tsne.js.
© 2017 by Paolo Caressa: http://www.caressa.it - @www_caressa_it
Powered by Shower Presentation Engine: https://shwr.me/#
Licenza: Creative Commons Attribuzione - Non commerciale 3.0 Unported