Lo speaker: una vita con...torta
Paolo Caressa - CODIN S.p.A.
Chieti, 13 dicembre 2017
Dipartimento di Scienze Giuridiche e Sociali
Università degli studi "Gabriele d'Annunzio"
Chieti, Mercoledì 13 Dicembre 2017
NB: lo studio dei casi (e qualche esempio di tecniche classiche) sarà svolto al di fuori di queste slide usando interattivamente dei programmi predisposti a questo scopo.
Fin dalle sue origini l’informatica è stata applicata allo studio del linguaggio, e lo studio del linguaggio è stato applicato all’informatica.
Infatti i computer sono programmati con linguaggi di programmazione, che sono "linguaggi formali", molto semplici rispetto alle lingue umane.
In particolare le teorie "generative" di Noam Chomsky sono state applicate con successo all’informatica e hanno consentito lo sviluppo dei linguaggi di programmazione moderni.
La teoria formale dei linguaggi, che si potrebbe chiamare anche "linguistica matematica" tenta di definire in modo generale i concetti linguistici che soggiacciono all’uso del linguaggio.
In particolare lo studio della sintassi e il suo legame con la teoria degli automi (gerarchie di Chomsky) ha consentito di ingegnerizzare la costruzione dei "compilatori", cioè i programmi che traducono da un linguaggio di programmazione al linguaggio della macchina.
Ma non di sola sintassi vive un linguaggio...
Le lingue sono caratterizzate da (C.W. Morris, 1938):
?


Per sé presa, la frase non è semplicemente ambigua, ma "anfibologica", cioè può avere due significati distinti a parità di sintassi: è il contesto, o l'intenzione del narratore, che consente di capire il significato vero.
Di ritorno dalla Corea riferì attonito: "ho visto mangiare un cane".
Dopo aver guardato dalla finestra, sulla strada, disse: "ho visto mangiare un cane"
(e se la finestra è in Corea?)
Riconoscere le strutture sintattiche: per esempio ricostruendo l'analisi logica di una frase, riconoscendo i lemmi dalle loro forme declinate, riconoscendo la categoria grammaticale di un simbolo ("stato" è sia verbo che sostantivo, etc.).
Qui si usano molto i metodi classici della linguistica computazionale e della teoria dei linguaggi formali, ma possono anche servire metodi euristici per esempio nel riconoscimento di lemmi a partire dalle parole, etc.
Riconoscere il significato di un testo: per esempio traducendolo in un formato di rappresentazione di dati e azioni (es: logica formale), traducendolo in un'altra lingua, generando sommari e sintesi di testi lunghi, etc.
Qui le tecniche di machine learning la fanno da padrone: tipicamente la difficoltà è definire la struttura di dati da usare per descrivere la semantica del testo per poi elaborarla con tecniche di ottimizzazione (= intelligenza artificiale).
Riconoscere il contesto d'uso di un testo: per esempio comprendendo se si tratta di un testo favorevole o meno a un certo argomento (sentiment analysis), trovando corrispondenza con altri testi che parlano dello stesso argomento (clustering), stabilendo di che argomento si parla, attribuendolo a un autore piuttosto che a un altro, etc.
Anche questo è un tipico campo d'azione per tecniche di machine learning, in particolare di classificazione e knowledge discovery.
") Il sillogismo categorico è una formalizzazione di un frammento del linguaggio per svolgere deduzioni in modo automatico:
Il sillogismo categorico è una formalizzazione di un frammento del linguaggio per svolgere deduzioni in modo automatico:
Socrate e Platone sono uomini
Gli uomini sono mortali
dunque
Socrate e Platone sono mortali
Indubitabile, no?
1858-1932")
Pietro e Giovanni sono apostoli
Gli apostoli sono dodici
dunque
Pietro e Giovanni sono dodici
Cosa abbiamo sbagliato?!?
Una interpretazione di un linguaggio è un modo di "mappare" il linguaggio su degli oggetti matematici, come per esempio gli insiemi
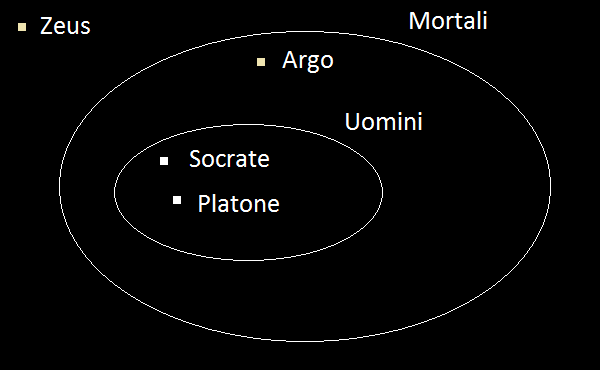
Socrate ∈ Uomini ∧ Platone ∈ Uomini,
Uomini ⊂ Mortali
⊦ Socrate ∈ Mortali ∧ Platone ∈ Mortali
Infatti se A e B sono insiemi, allora A ⊂ B se e solo se per ogni x ∈ A si ha pure che x ∈ B.
Nel caso dei "dodici apostoli", il dire "gli apostoli sono dodici" è una abbreviazione per "la cardinalità dell'insieme degli apostoli è 12": dunque la seconda affermazione è "fuori dal modello", in quanto non è insiemistica ma numerica. Una possibile formalizzazione diviene
Pietro ∈ Apostoli ∧ Giovanni ∈ Apostoli,
Card(Apostoli) = 12
⊦ Card({Pietro, Giovanni}) = 12
che è una falsa deduzione.
Una corretta formalizzazione logico-matematica consente di sciogliere l'ambiguità linguistica e di dirimere i domini semantici di ciascuna frase: le proprietà matematiche dei domini semantici consentono poi di spiegare il paradosso.
Questo semplice esempio mostra come si possa studiare (parte di) un linguaggio usando i sistemi formali della logica matematica per la sintassi e la teoria degli insiemi, o dei suoi frammenti, per la semantica.
Ecco perché, da millenni, lo studio del linguaggio è stato oggetto di ricerche da parte di logici, filosofi e matematici (o varie combinazioni dei tre) e queste ricerche hanno anche avuto un diretto influsso sulla scienza dei calcolatori
Per esempio abbiamo già citato la teoria di Noam Chomsky dei linguaggi generati da particolari classi di grammatiche che ha influenzato profondamente la computer science e che costituisce ancora un argomento portante dell'informatica teorica.
")
For a large class of cases of the employment of the word ‘meaning’—though not for all—this word can be explained in this way: the meaning of a word is its use in the language
(Postumo)
") People speak of catching the proper, true meaning of a notion, something independent of actual usage, and independent of any normative proposals, something like the platonic idea behind the notion. This last approach is so foreign and strange to me that I shall simply ignore it for I cannot say anything intelligent on such matters
People speak of catching the proper, true meaning of a notion, something independent of actual usage, and independent of any normative proposals, something like the platonic idea behind the notion. This last approach is so foreign and strange to me that I shall simply ignore it for I cannot say anything intelligent on such matters
(1966)
") There is in my opinion no important theoretical difference between natural languages and the artificial languages of logicians; indeed I consider it possible to comprehend the syntax and semantics of both kinds of languages with a single natural and mathematically precise theory.
There is in my opinion no important theoretical difference between natural languages and the artificial languages of logicians; indeed I consider it possible to comprehend the syntax and semantics of both kinds of languages with a single natural and mathematically precise theory.
(1970)
[https://plato.stanford.edu/entries/word-meaning/]
I matematici, i logici (e appresso gli informatici) per assegnare un significato ai loro linguaggi formali definiscono una funzione di interpretazione:
F : Testi → Dominio
dove Testi è l'insieme di tutte le stringhe sintatticamente corrette del linguaggio e Dominio è un insieme che contiene tutte le cose di cui il linguaggio può parlare.
Questo approccio è molto efficace nel caso dei linguaggi di programmazione. Nel caso delle lingue naturali, il Dominio è costituito da tutto ciò di cui si possa parlare (gnomi, etc.).
Dunque dare una semantica per un linguaggio può essere pensato come fornire un mondo del quale parlare al linguaggio stesso: un altro modo di esprimerlo è dire che le strutture sintattiche del linguaggio vengono "mappate" su oggetti che riflettono le relazioni semantiche espresse dalle relazioni sintattiche.
Gli oggetti matematici più semplici ai quali far corrispondere in questo modo i simboli di un linguaggio sono numeri, vettori, matrici, etc. Questi hanno il vantaggio di poter essere trattati efficientemente dai computer.
I metodi della linguistica computazionale e della logica formale consentono di ottenere buoni risultati per quel che riguarda la sintassi ma non sembrano effettivi per la semantica: tipicamente questo approccio coinvolge strutture di dati complesse, la cui struttura dipende sostanzialmente dalla grammatica della lingua che si vuole analizzare.
Questi metodi, per esempio l'approggio generativo di Noam Chomsky, sono teoricamente e praticamente efficaci nello studio dei linguaggi formali (per esempio i linguaggi di programmazione).
Se i metodi formali della "linguistica matematica" danno risultati interessanti nel quadro della sintassi del linguaggio, dal punto di vista della semantica non offrono lo stesso grado di precisione e solidità teorica.
Il loro principale limite sta nella generalità dell’approccio: si tenta di definire cosa sia una grammatica per tutte le lingue, il che rende molto difficile definire la semantica, con tutte le sue sfumature, per l’elevato livello di generalità.
Una idea è quindi rinunciare alla generalità e partire dai testi.
A partire dagli anni '90, grazie alla crescente capacità computazionale e alla rinascita dell'Intelligenza Artificiale, si sono potuti applicare metodi di ottimizzazione e di inferenza statistica a collezioni molto ampie di testi.
A differenza dei metodi formali, il fulcro di questo approccio è associare ai termini linguistici degli oggetti numerici (per esempio numeri, vettori, etc.) per poterli poi elaborare con gli algoritmi di ottimizzazione (=Intelligenza Artificiale).
Questi metodi sono tipicamente indipendenti dalla lingua.
Il concetto di base del machine learning è che problemi molto complessi non sono passibili di una descrizione teorica e generale, ma ne sono noti solo i casi particolari che si possono osservare.
Quindi, anziché usare i computer per codificare algoritmi basati su un modello teorico a priori, li si può programmare per utilizzare gli esempi del problema, e poi ricostruire, a posteriori, un modello (matematico o statistico), sulla base di questi esempi.
Questi algoritmi "a posteriori" hanno bisogno di un "addestramento" (training) per far convergere il modello matematico che costruiscono sulla base degli esempi che sono loro sottoposti.
Per questo si dice che "apprendono", in quanto modificano i propri parametri interni sulla base degli esempi che vedono in modo da riuscire a risolvere il problema su questi esempi e sperare che il modello numerico che si sono costruiti per farlo funzioni anche su altri esempi analoghi.
Le idee essenziali sul machine learning risalgono agli anni ‘50 e ‘60. Ma è soltanto dalla fine degli anni ‘90 che la capacità di memoria e calcolo delle macchine è in grado di sfruttarne la potenza appieno.
E, soprattutto, è soltanto con l’avvento di Internet che si è resa disponibile una quantità astronomica di dati disponibili da elaborare.
Questi algoritmi infatti sono tanto più efficienti quanti più dati riescono a "macinare".
È sempre una buona idea, per approcciare un argomento e capirne le potenzialità guardare agli esempi più semplici ed elementari, dove spesso si trovano, in nuce, i concetti poi sviluppati in modo più complesso e avanzato.
Nel caso dell’analisi statistica dei testi è possibile farsi una idea delle potenzialità del campo guardando i risultati non disprezzabili che si possono ottenere con tecniche molto elementari.
È quello che faremo nelle prossime slide.
Una prima idea per far emergere la "semantica" di un testo, è notare che le parole in una frase sono disposte in un certo ordine, dettato dalle regole grammaticali e da ciò che si vuole esprimere.
Pertanto, nella sequenza delle parole di un testo, dopo una parola non ne segue una qualsiasi altra della lingua, ma solo quelle che ha senso porre dopo la parola data, sia per rispettare la grammatica che per rispettare il senso.
Abbiamo detto che l’ordinamento nella successione delle parole di un testo ne codifica in qualche modo sia la grammatica che la semantica.
Per esempio, prima del verbo va solitamente un soggetto: quindi dopo Il gatto figurerà un verbo. Tuttavia la frase
Il gatto vola
è corretta grammaticalmente ma non lo è dal punto di vista semantico.
")
L’idea dei modelli "markoviani" è che, in una lingua naturale, una parola può essere solo seguita da certe parole e mai da altre.
Formalmente, se w1, w2, ..., wN sono tutte le parole di un linguaggio, possiamo definire la matrice P=|pij| i cui elementi pij definiscono la probabilità che la parola wi segua la parola wj.
Può quindi accadere, e tipicamente accade, che pij = 0 se alla parola wi non può mai seguire la parola wj.
Per stimare questa matrice P si potrebbero prendere un gran numero di documenti scritti nella lingua che si vuole analizzare e procedere come segue:
pij = #{volte che wi segue wj}
#{volte che wi segue una parola}
Si tratta di un modo "frequentista" di stimare le probabilità che costituiscono gli elementi della matrice P.
Le righe della matrice P sono vettori stocastici (cioè la somma dei loro elementi è 1).
Possiamo quindi interpretare la riga Pj = |pij| come la distribuzione di probabilità di occorrenza delle parole che precedono wi.
Morale: data una parola del corpus, e facendo sampling dall’insieme di tutte le parole secondo la distribuzione data dalla riga di P corrispondente alla parola, possiamo generare sequenze di parole che sono "possibili" nel linguaggio dato.
Usiamo questa tecnica per un esperimento un po’ surreale, che riassumo di qui seguito:
Il seguente programma, scritto in Python, consente di svolgere questo compito (in realtà non costruisce esplicitamente la matrice ma calcola le probabilità "on the fly"):
gramsci.py programma di conversazione
markov.py implementazione del modello markoviano
gramsci.txt file con gli scritti di Gramsci.
Ovviamente il risultato non ha molto senso: in questo caso si generano 5 parole per ogni parola data, per consentire frasi parzialmente sensate. Per questo il programma si chiama "Conversazione con un pazzo che si crede Gramsci".

Si noti che i valori della matrice P = |pij| possono vedersi come le probabilità P(wi|wj) di occorrenza di wi condizionata all’occorrenza di wj.
Sorge quindi l’idea di utilizzare una tecnica deduttiva fondamentale in moltissimi campi applicativi anche per studiare la struttura statistica di un linguaggio sulla base di testi scritti per mezzo di esso: il teorema di Bayes.
")
Ricordiamo brevemente come si applica il teorema di Bayes: supponiamo di avere un insieme di ipotesi h1, ..., h2 relative a dei dati (o osservazioni) d.
Vogliamo scegliere l’ipotesi più probabile dato d, quindi scegliere l’hi per cui è massima la probabilità P(hi|d).
Il problema è che tipicamente questa probabilità a posteriori non è immediatamente nota: si pensi all’esempio di una malattia (h) da dedurre in base ai sintomi (d); solitamente sappiamo stimare la probabilità di avere certi sintomi data la presenza della malattia, cioè P(d|hi).
Il teorema di Bayes consente di calcolare la probabilità a posteriori di hi date le sue probabilità a priori:
P(hi|d) = P(d|hi) P(hi) / P(d)
NB: non sorprende che P(hi|d) sia proporzionale a P(hi) ed a P(d|hi). Inoltre, più è elevata la probabilità a priori di d, che quindi sia osservata indipendentemente da hi, e più decresce la probabilità a posteriori P(hi|d).
A questo punto, possiamo calcolare le probabilità a posteriori per ciascuna ipotesi e scegliere quella che le massimizza:
hbest = argmax P(hi|d)
i
= argmax P(d|hi) P(hi) / P(d)
i
= argmax P(d|hi) P(hi)
i
NB: se le hi sono equiprobabili abbiamo la Maximum Likelihood (in quanto possiamo non considerare P(hi) nel calcolare l'indice i per il quale l'argomento è massimo).
Una classica applicazione dei modelli bayesiani alla elaborazione digitale dei testi ne concerne la classificazione.
Vogliamo cioè assegnare dei "tag" a documenti di testo in modo che documenti che hanno un contenuto analogo condividano lo stesso tag.
Per mostrare in concreto questo esempio ben noto, l’abbiamo implementato formulando le seguenti ipotesi:
Ma l’ipotesi più forte (e inverosimile) è la seguente:
Nell’applicare l’algoritmo di Bayes
hbest = argmax P(d|hi) P(hi)
i
d è nel nostro caso una funzione, determinata dall’insieme {d(1),...,d(n)} dei suoi valori. A priori non è detto che questi valori siano indipendenti (per esempio a un articolo seguirà un nome): l’ipotesi "ingenua" è che lo siano e quindi
hbest = argmax [P(d(1)|hi) ... P(d(n)|hi)] P(hi)
i
(Ricordiamo che a e b sono indipendenti se P(a|b) = P(a) e P(b|a) = P(b), da cui segue che P(a,b) = P(a)P(b).)
L’ipotesi "ingenua" è quindi in questo caso che le posizioni delle parole non influenzano le loro probabilità di comparire in una data posizione.
Questo è chiaramente falso ed è la negazione dell’ipotesi alla base del modello markoviano.
Tuttavia questa palese falsità semplifica computazionalmente l’algoritmo in modo formidabile.
Nel caso specifico dei documenti di testo, questa ipotesi si può formalizzare come
P(d(h)=w|hi) = P(d(k)=w|hi)
Cioè, data una classe, le parole di un documento hanno la stessa probabilità a posteriori di comparire indipendentemente dalla posizione che occupano nel documento.
In questo modo possiamo stimare le probabilità P(d(h)=w|hi) semplicemente come P(w|hi), cioè calcolando la frequenza di w in tutti i documenti della classe hi e dividendola per tutte le parole che occorrono in quella classe.
Un miglioramento di questa stima è
P(w|hi) = #{occorrenze di w in hi} + 1
#{occorrenze qualsiasi in hi} + #{parole}
L’algoritmo "naive Bayes" richiede un "addestramento" su un insieme di documenti la cui classificazione sia nota.
Si tratta cioè di un algoritmo di machine learning supervisionato, che per poter esprimere un parere su dati di classificazione ignota deve aver elaborato numerosi esempi classificati.
Precisamente, l’algoritmo ha necessità di un numero sufficiente di documenti classificati per poter stimare le probabilità a posteriori.
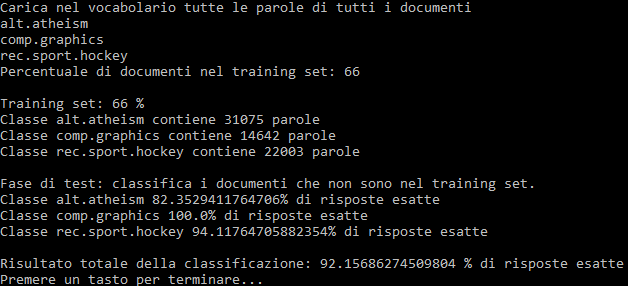
Nel nostro caso abbiamo usato il classico repository "20 newsgroups", che contiene 20.000 documenti di testo tratti da news degli anni ‘90.
Ciascuna si riferisce a delle categorie particolari di interesse, 20 in tutto, e ciascuna contiene 1.000 documenti.
Scegliendo come training set 2/3 del corpus, vale a dire i primi 666 documenti, e lasciando i restanti 334 come testing set, abbiamo ottenuto una percentuale di 80% di classificazioni corrette su esempi che il programma non aveva incontrato prima.
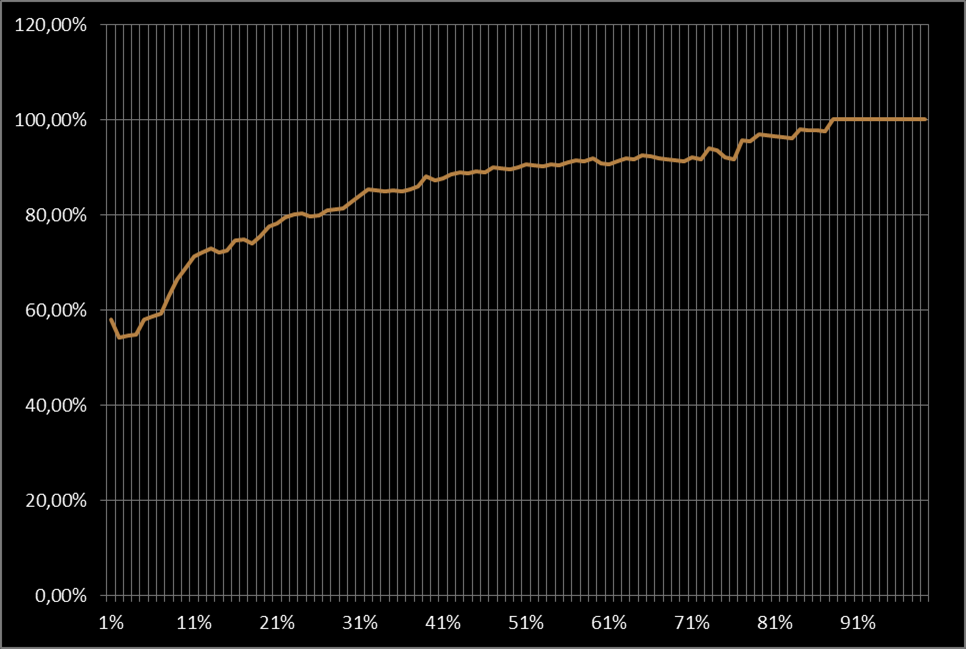
Limitandosi a sole tre classi e 100 file in totale per ogni classe si può mostrare facilmente come varia la percentuale di risposte esatte E rispetto alla percentuale di documenti utilizzati per il training T.
Si verifica che
Nel grafico seguente, sulle ascisse i valori di T, sulle ordinate le risposte esatte corrispondenti.
Per provare il programma, va messo in una cartella che contiene una cartella con i file del dataset, ciascuno in una sottocartella rappresentante la classe corrispondente.
nbayes_test.py il programma che svolge il test (chiede in input la percentuale di documenti in una classe usati per il training)
nbayes.py la libreria che calcola naive Bayes
20 Newsgroup dataset su cui provare il programma (che deve stare nella stessa cartella in cui si decomprime il file)
Nella slide seguente il risultato dell'esecuzione del programma nel caso di 3 classi e 100 documenti per classe:
J.L. Lagrange ebbe a dire di A. Lavoisier che il suo grande merito era stato di rendere la chimica facile come l’algebra.


Le tecniche di "word embedding" provano a fare la stessa cosa con l’analisi dei testi: derivano in realtà da classiche tecniche di "information retrieval" degli anni ’60 la cui idea è di codificare un documento con un punto in uno spazio di dimensione abbastanza alta.
Precisamente, si sceglie una dimensione N (alta) e si prova a "mappare" le parole di un corpus di documenti sui punti di uno spazio a N dimensioni, in modo che le relazioni semantiche fra le parole si trasformino in relazioni algebriche fra questi punti.
Il principale modello matematico per qualsiasi cosa si possa immaginare è lo spazio vettoriale, cioè un insieme di oggetti (chiamati punti o vettori) che si possono sommare fra loro e moltiplicare per numeri in modo che valgano le usuali regole dell'algebra dei vettori nel piano e nello spazio: ogni spazio vettoriale ha una ben precisa dimensione.
La teoria degli spazi vettoriali è particolarmente semplice in quanto è "categorica": fissata una dimensione tutti gli spazi vettoriali di quella dimensione sono equivalenti fra loro (i matematici dicono isomorfi).
Il "modello standard" di uno spazio vettoriale di dimensione N è l'insieme RN delle N-ple ordinate di numeri reali (x1, ..., xN): nei casi N=2, N=3 ritroviamo il classico concetto di piano e spazio cartesiano.
Possiamo dotare questo insieme di operazioni indotte "termine a termine" da quelle fra numeri (α è un numero)
(x1, ..., xN) + (y1, ..., yN) = (x1+y1, ..., xN+yN)
α(x1, ..., xN) = (αx1, ..., αxN)
x=(,) y=(,) x+y=(0,0)
La lunghezza (euclidea) di un vettore è il numero non negativo
______________
|x| = √x12 + ... + xN2
Esistono altre possibili distanze (tutte topologicamente equivalenti).
Questa è direttamente ispirata al teorema di Pitagora e corrisponde, nel piano e nello spazio cartesiani, alla usuale distanza euclidea.
La distanza (euclidea) fra due vettori è la lunghezza della loro differenza
________________________
d(x,y) = |x-y| = √(x1-y1)2 + ... + (xN-yN)2
Se due vettori hanno distanza minore di δ allora vuol dire che uno dei due è sempre incluso in ogni "palla" di centro l'altro e raggio maggiore di δ.
La correlazione (o "similarità") fra due vettori è un numero fra -1 e 1 ottenuto come
c(x,y) = x1y1 + ... + xNyN
|x|×|y|
Questo valore si chiama anche "distanza del coseno", essendo pari al coseno dell'angolo fra i due vettori: questo angolo è 1 se i vettori sono allineati, -1 se sono opposti, 0 se sono ortogonali.
x = (,)
y = (,)
d(x,y) = 0
c(x,y) = 0
Se abbiamo un insieme di oggetti possiamo mapparli sui punti di uno spazio vettoriale di dimensione N in molti modi: la "furbizia" nella scelta del modello sta nel farlo in modo che oggetti simili siano mappati su punti vicini, nel senso che la loro distanza è piccola.
Questi modelli si chiamano modelli continui perché i valori delle componenti dei vettori variano fra i numeri reali (rappresentabili nel computer); incidentalmente, la funzione che applica gli oggetti sui punti del modello vettoriale dovrebbe essere tale che punti vicini nel modello provengono da punti vicini nel dominio.
Tipicamente i modelli vettoriali sono tanto più precisi ed espressivi quanto maggiore è la dimensione degli spazi vettoriali coinvolti: per esempio, un modo per codificare un documento di testo potrebbe essere mapparlo su un punto di uno spazio vettoriale a N dimensioni dove N è il numero di parole possibili per quel documento.
Naturalmente questo implica dover, a priori, considerare spazi vettoriali di dimensioni dell'ordine delle migliaia, decine di migliaia o anche centinana di migliaia.
Per questo si applicano delle tecniche di "riduzione della dimensione" che consentono di proiettare questi spazi su spazi con basse dimensioni mantenendo in qualche modo la coerenza e il significato dei dati rappresentati.
Esempi di queste tecniche sono:
Se abbiamo un corpus {D1,...,Dk} di documenti di testo, e se {W1,...,Wh} sono le parole che occorrono almeno una volta in qualche documento, possiamo formare una matrice
| D1 | ... | Dk | |
|---|---|---|---|
| W1 | x11 | ... | x1k |
| ⁝ | ⁝ | ⁝ | ⁝ |
| Wh | xh1 | ... | xhk |
dove xij è un numero (solitamente fra 0 e 1) che descrive la rilevanza della parola Wi per il documento Dj.
Per popolare la matrice precedente (migliaia/miriadi di righe, centinaia/migliaia di colonne) si possono usare diverse misure della rilevanza di una parola in un testo e in un corpus di testi: un esempio classico è la TFIDF:
xij = #{occorrenze di Wi in Dj} ×
× log (k / #{documenti D tali che Wi ∈ D})
Si premiano i termini che compaiono spesso in un documento ma non troppo spesso negli altri documenti, cioè le parole che "caratterizzano" un documento nel corpus.
Lo schema precedente (che viene dalle classiche tecniche di "recupero informazioni") può essere usato per determinare un modello semantico delle parole di un corpus, considerando come documenti non interi testi ma delle "finestre" di parole costruite attorno alla parola da analizzare.
In questo modo, il contesto di una parola sono le parole che occorrono nelle "vicinanze" di essa in un testo (per esempio fra le 5 parole che la precedono e le 5 che la seguono): la matrice diviene dunque una "matrice di co-occorrenze".
Si tratta di una tecnica che consiste nell'analizzare un corpus estraendone parole e contesti, usandoli per formare la matrice che poi viene ridotta nelle sue dimensioni usando algoritmi di algebra lineare (SVD).
Le righe di questa matrice ridotta costituiscono quindi dei vettori numerici associati alle parole, che ne codificano la semantica, in modo che parole con significato analogo tendono a essere rappresentate da vettori "vicini" fra loro nel senso della distanza euclidea, o della correlazione.
")
A word is characterized by the company it keeps
John Rupert Firth (1890-1960)
") The correlation between language and meaning is much greater when we
consider connected discourse. To the extent that formal (distributional) structure
can be discovered in discourse, it correlates in some way with the substance of
what is being said; this is especially evident in stylized scientific discourse.
The correlation between language and meaning is much greater when we
consider connected discourse. To the extent that formal (distributional) structure
can be discovered in discourse, it correlates in some way with the substance of
what is being said; this is especially evident in stylized scientific discourse.
Zellig Harris (1909-1992)
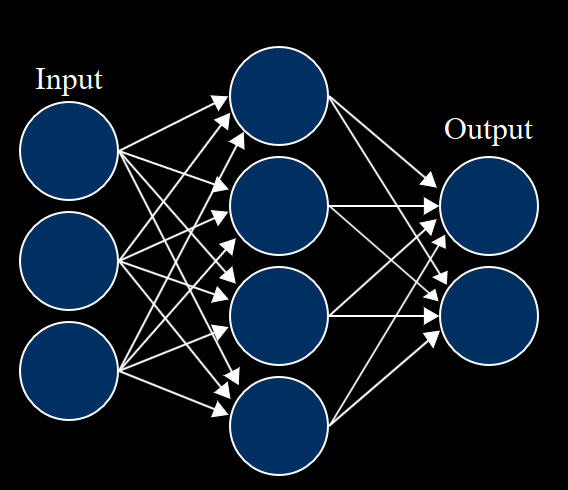
Una rete neurale è un particolare tipo di algoritmo iterativo la cui struttura mima in maniera iper-semplificata un modello del funzionamento cerebrale.
L'idea è che la rete è composta da una serie di neuroni che sono disposti in strati: uno strato di input prende i dati dal "mondo esterno", gli strati interni elaborano l'informazione e uno strato di output emette un risultato.
Ciascuno strato è composto da neuroni che lavorano in parallelo e che sono collegati ai neuroni dello strato precedente e dello strato seguente.
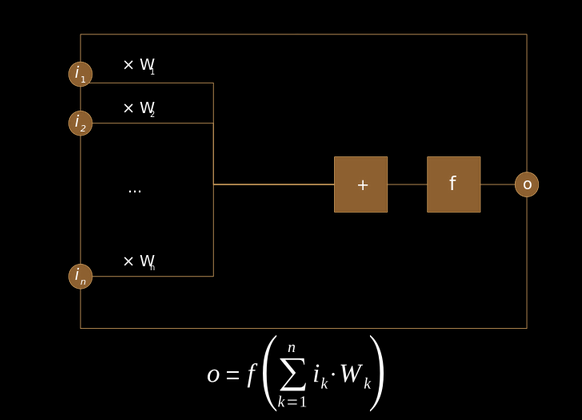
Il modello di un neurone artificiale, il mattone col quale si costruisce una rete neurale, è stato ideato negli anni 1940 e può rappresentarsi con un vettore (w1, w2, ..., wn) che accetta in input una serie di numeri x1, x2, ..., xn (prodotti da altri neuroni o immessi nella rete dall'esterno) e fornisce in output un singolo numero combinando questi numeri:
output = f(x1w1 + x2w2 + ... + xnwn)
dove f è una funzione non lineare (si noti che pesi e input sono combinati calcolandone la correlazione come vettori).
Un neurone si attiva quando le sue terminazioni di input sono stimolate dai neuroni del layer precedente oltre una certa soglia.
Una volta attivato, il neurone emette a sua volta un segnale in output che è il risultato di una funzione non lineare applicata ai suoi input.
In questo modo i segnali inviati allo strato di input si propagano all'interno della rete fino allo strato di output: i neuroni di quest'ultimo strato costituiscono il risultato del calcolo effettuato dalla rete.
I valori dei pesi della rete di neuroni determinano come i singoli neuroni reagiscono agli stimoli di input e quale risultato producono in output: questi valori sono quindi quelli responsabili del calcolo effettivo tramite la rete.
I pesi si possono modificare e si devono modificare, in quanto la rete è generalmente inizializzata a dei valori casuali bassi nei suoi pesi, che sono poi modificati con un algoritmo chiamato "backpropagation" in modo da modificarsi per migliorare le proprie prestazioni nel fornire, dato un input, l'output corretto.
Per far svolgere a una rete un calcolo ben determinato, le si sottopongono dei "training example", cioè degli input per i quali si sa la risposta attesa e vedere cosa risponde la rete: se la risposta della rete non è quella attesa si modificano i pesi della rete in modo da "costringerla" la prossima volta a rispondere in modo corretto per quel determinato input.
Disponendo di un training set abbastanza esteso, la rete potrà "allenarsi" a riconoscere una gran varietà di input e fornire l'output corrispondente. Una volta addestrata a sufficienza, potrà essere usata su input per i quali la risposta non è nota.
Una rete neurale, vista come scatola nera, accetta dei numeri in input e fornisce dei numeri in output: possiamo quindi pensarla come una funzione vettoriale di più variabili, e in effetti qualsiasi funzione vettoriale continua può essere approssimata da una rete neurale.
Questo vuol dire che a furia di far girare la rete su training data, se questi dati sono abbastanza numerosi, i pesi della rete convergeranno verso dei valori stabili consentendo di calcolare in modo approssimato a piacere il valore della funzione in un qualsiasi punto.
Qualsiasi problema esprimibile come approssimazione di una funzione ignota a partire dai valori che assume può essere affrontato con una opportuna rete neurale.
Poiché qualsiasi informazione rappresentabile in un computer viene digitalizzata (letteralmente trasformata in numeri) è chiaro quindi come le reti neurali possano essere impiegate per riconoscere, approssimare o anche generare immagini, suoni e testi.
In particolare, come abbiamo visto, un documento di testo può essere trasformato in un vettore, quindi può essere elaborato da una rete neurale.
Se trasformiamo l'output della rete in un valore di probabilità (e ci sono varie tecniche per farlo partendo da una rete che emette semplicemente dei numeri in output), allora possiamo anche addestrarla in modo "non supervisionato".
Più precisamente potremmo produrre un training set facendo sampling da una distribuzione piuttosto che etichettando manualmente i singoli documenti del training set: questo è l'approccio dell'algoritmo che vogliamo descrivere.
Le reti neurali "classiche" non hanno memoria, nel senso che il valore dei loro pesi al tempo t1 dipende soltanto dal valore che avevano al tempo t0 e, ovviamente, dall'ultimo training example che è stato sottoposto alla rete.
Una rete ricorrente ha invece alcuni neuroni al suo interno che forniscono un ulteriore input alla rete e che sono alimentati dall'output: questi neuroni formano una sorta di "memoria storica" di quanto accaduto alla rete.
Queste reti sono usate con successo nella predizione delle serie storiche.

Una rete ricorrente con tre neuroni: uno di input, uno di output e uno interno che si "autoalimenta". A destra un suo "unfolding" in due istanti.
Le reti ricorrenti sono state impiegate con molto successo nella comprensione e anche nella generazione di testi: pensando ai nostri esempi elementari (markoviani e bayesiani) possiamo immaginare quanto un modello non lineare come una rete ricorrente possa migliorare le prestazioni di sistemi di generazione di testi e di classificazione e comprensione dei testi.
Combinando comprensione, generazione e il fatto che questi sistemi non dipendono dalla lingua, è chiaro il perché siano utilizzati per la traduzione automatica da una lingua a un'altra.
Veniamo alla rete di nostro interesse: Word2Vector. Si tratta di una una rete neurale ricorrente con un layer interno, che viene usata in una modalità non supervisionata.
In pratica, per ogni parola del corpus si produce un vettore binario w, di dimensione pari alla cardinalità N del corpus, che rappresenta la parola e lo si usa come input per la rete, che in output fornisce una distribuzione di probabilità y sullo "spazio" delle parole, dunque ancora un vettore di dimensione N.
La rete si addestra a produrre la distribuzione di probabilità y in modo che dalla parola di input si possa predire il contesto (skipgram model): in alternativa si può addestrare la rete a dedurre la parola dal contesto (CBOW model).
Si noti che l'approccio markoviano di dedurre una parola data la precedente è un caso lineare e particolare di questi due.
Il layer interno della rete neurale accumula dei valori prodotti via via che le parole del testo sono presentate alla rete, e conserva quindi memoria dei contesti al cui interno si manifestano le parole esaminate dalla rete: questo è l'elemento cruciale dell'algoritmo.
")
s(t) = Uw(t) + Ws(t-1)
y(t) = Vs(t)
Sia y che s sono filtrati tramite delle funzioni: con la rappresentazione "soft-max" il primo, con una sigmoide f(z) il secondo.
")
")
I vettori associati alle parole, cioè il reale output che interessa per il modello semantico distribuito, sono estratti come colonne dalla matrice U che fornisce il collegamento fra il layer di input e il layer interno della rete neurale.
Questo algoritmo può essere implementato in modo efficiente e, per corpus abbastanza vasti (almeno miliardi di parole), produce risultati molto accurati migliorando di molto le prestazioni dei precedenti algoritmi di analisi semantica distribuita.
Un aspetto che ha del miracoloso di questo algoritmo è che alcune relazioni semantiche sono codificate tramite operazioni lineari fra i vettori delle parole corrispondenti.
Per esempio: se scriviamo v(w) per il vettore associato alla parola w, e w(v) per la parola corrispondente al vettore più vicino al vettore v, troviamo che
w(v("king") - v("man") + v("woman")) = "queen"Ulteriori risultati ottenuti dagli inventori di Word2Vector.
w(v("bigger") - v("big") + v("cold")) = "colder"w(v("Paris") - v("France") + v("Italy")) = "Rome"w(v("sushi") - v("Japan") + v("Germany")) = "bratwurst"w(v("Windows") - v("Microsoft") + v("Google")) = "Android"L'algoritmo Word2Vector è stato implementato da uno dei suoi creatori, Tomas Mikolov, in un C duro e puro, e si scarica dal sito di Google: https://code.google.com/archive/p/word2vec/.
Dal sito si scarica il file .c del programma che produce i vettori, altri programmi che illustrano possibili e semplici applicazioni di questi vettori, e link a dataset, anche di miliardi di parole, per addestrare l'algoritmo.
Per la sessione interattiva di questa presentazione ho prodotto dei programmi di wrapping che consentiranno di studiare alcuni casi interessanti usando word2vec.
Come "assaggio preliminare, in queste slide ho usato un dataset "piccolo" (70K parole, dimensione 200) in lingua inglese, pertanto le performance degli script seguenti non saranno esaltanti, ma rendono l'idea: con corpus da milioni di vettori e una dimensione di almeno 300 si ottengono risultati migliori, con miliardi di vettori e almeno 400 dimensioni si hanno performance spettacolari.
I programmini JavaScript nelle slide seguenti mostrano come alcune relazioni semantiche si codifichino in relazioni lineari: per esibire in 2D i risultati ho usato l'algoritmo t-SNE per proiettare i vettori di 200 componenti nel piano.
Semantica dell'analogia codificata nei vettori: si determina una parola che ne corrisponde a un'altra dato un certo schema di corrispondenza: questo semplicemente con operazioni lineari!
sta a come sta a ...
Notiamo che è come risolvere una "proporzione" fra parole: a sta a b come c sta a ...
Usando la correlazione possiamo determinare le k= parole più simili a una parola data:
I limiti di calcolo del brower e di lentezza di JavaScript non consentono esempi più realistici: per questo la sessione "espositiva" di questo evento termina qui, per passare a una sessione "pratica" eseguendo programmi in modalità interattiva.
Abbiamo selezionato alcuni dataset di parole liberamente disponibili per la nostra dimostrazione: per l'italiano Paisà.
Nelle slide seguenti le spiegazioni di alcuni esperimenti che si possono eseguire usando i tool messi a disposizione dalla distribuzione di word2vec.
Con il tool distance filebin si possono individuare le parole più correlate con una parola data (in quanto il tool ne calcola la "distanza del coseno" cioè la correlazione).
Con il tool word-analogy filebin vengono chieste tre parole e calcolata la quarta secondo lo schema che abbiamo visto in precedenza ("proporzione fra parole").
Il programma word2vec consente inoltre, con l'opzione -classes di specificare un numero di cluster nei quali collezionare tutte le parole del corpus analizzato: questo clustering è eseguito con la tecnica k-means e i cluster sono etichettati con dei numeri.
Credits
Wikipedia, http://www.meteoweb.eu per le immagini.
Jason Rennie per il dataset utilizzato per naive Bayes.
Matt Mahoney per il dataset utilizzato per word2vec.
Google Code per il codice di Word2Vector.
Tomas Mikolow per l'algoritmo, il codice e i paper di riferimento (da alcune sue slide abbiamo preso delle figure).
Matt Mahoney per il dataset utilizzato per word2vec.
Andrej Karpathy per la libreria tsne.js.
Progetto PAISÀ per il dataset non usato in queste slide ma nella sessione pratica.
© 2017 by Paolo Caressa: http://www.caressa.it - @www_caressa_it
Powered by Shower Presentation Engine: https://shwr.me/#
Licenza: Creative Commons Attribuzione - Non commerciale 3.0 Unported